Chain of Thought(CoT)は、中間的な推論ステップを利用して、最終的な答えを予測する手法です。
背景
近年、言語モデルの規模を拡大することが、自然言語処理(NLP)タスクのパフォーマンスを向上させる確実な方法であることが示されています。
今日、100B以上のパラメータを持つ言語モデルは、追加でトレーニングをしなくても、感情分析や機械翻訳のようなタスクで高い性能を達成しています。しかし、このような大規模言語モデルであっても、数学の単語問題や常識的推論など、特定の多段階推論タスクでは、十分な性能が得られていないのが現状です。
また、思考の連鎖を実現するために、これまでファインチューニングが利用されてきました。しかし、ファインチューニングの方法では、高品質の大規模なデータセットを作成するコストがかかります。
さらに、Few shot promptingの手法では、推論能力を必要とするタスクではうまく機能せず、言語モデルの規模が大きくなっても実質的に改善しないことが多いことがわかっています。
Chain-of-Thought(CoT)とは
GPT-3によって普及した標準的なプロンプト(Few shot promptingの手法)では、モデルに入出力ペア(質問と答えの形式)を与えられてから、答えを予測します(下図左)。
Chain of Thought(CoT)におけるプロンプト(下図右)では、最終的な答えを予測する前に、中間的な推論ステップである「思考プロセス」を、言語モデルの入力として与えます。
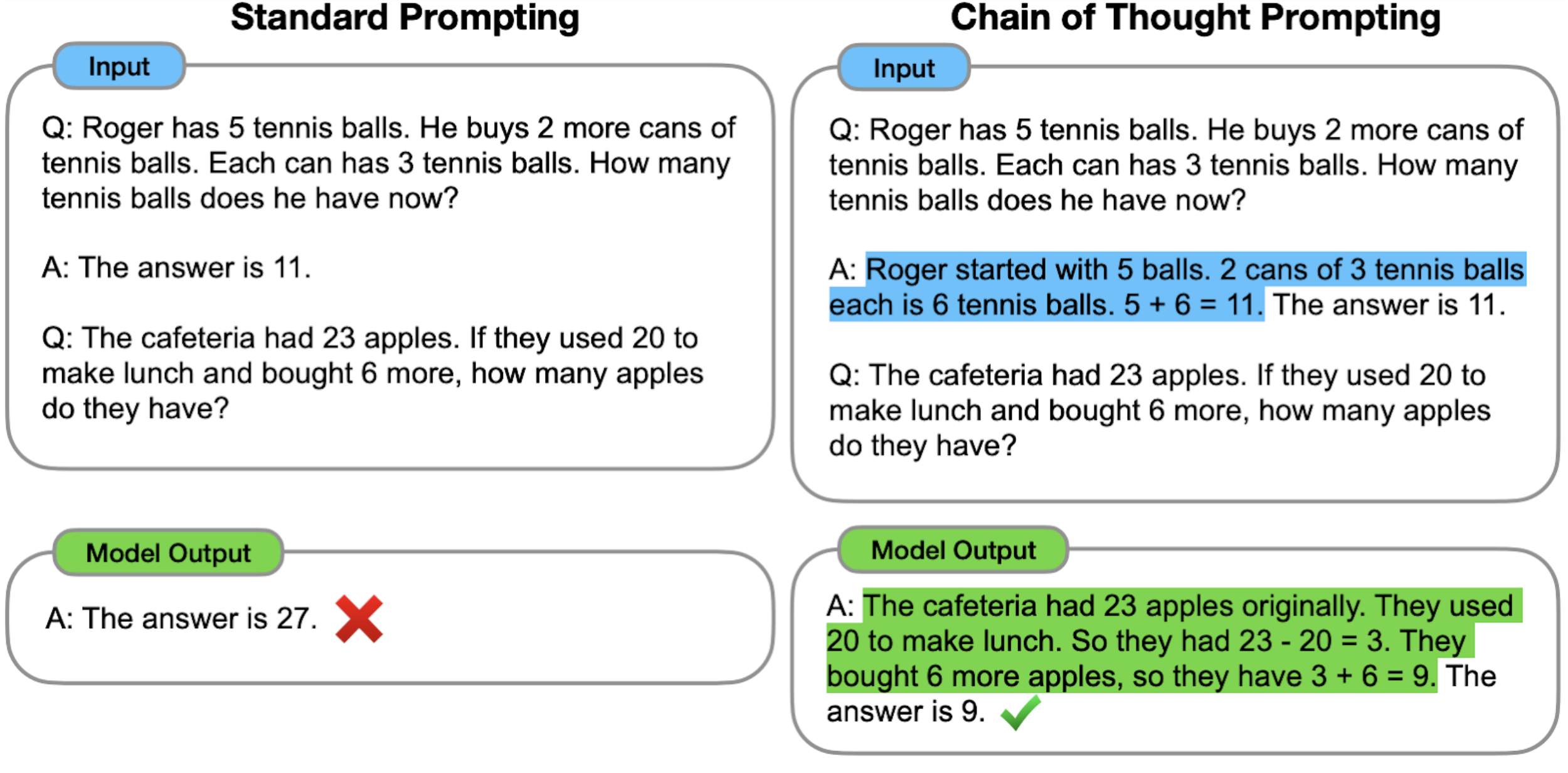
Chain of Thought(CoT)を理解するために、数学などの複雑な推理課題を解くときの「思考プロセス」を考えてみましょう。「思考プロセス」では、問題を中間ステップに分解し、それぞれを解いてから最終的な答えを出すのが一般的です。
たとえば、上記の例の「思考プロセス」は、「ジェーンがお母さんに花を2つ贈った後、彼女は10個持っているとします。そして、お父さんに3つ贈った後、彼女は7個持っていました。だから彼女が最終的に持っていた花の数は7個である。」ということになります。
この論文の目的は、このような「思考プロセス」、つまり問題の最終的な答えを導く一連の一貫した中間推論ステップを入力に与えることです。
Chain of Thought(CoT)における「思考プロセス」は、人が言語を使って解決できるあらゆるタスクに適用できます。
実験
Chain of Thought(CoT)を、パラメータが422Mから137BのLaMDA言語モデルと、パラメータが8Bから540BのPaLM言語モデルの両方を用いて評価を行います。
このとき、Chain of Thought(CoT)の「思考プロセス」を手作業で作成しました。
そして、算術推論と、常識推論について、実験を行いました。
ベースラインとして、Few shot promptingを用いました。Few shot promptingは、このプロンプトでは、予測をするときに、いくつかの入力と出力のペアも同時に与える方法です。
結果
算術推理
算数推論のベンチマークであるMultiArithとGSM8Kを用いて、評価が行われました。
これらによって、多段階の算数の問題を解く能力をテストします。
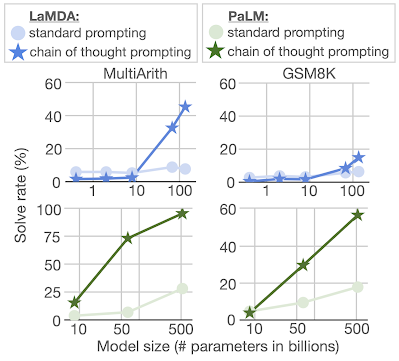
これらの2つのベンチマークでは、標準的なプロンプトを使用すると、パラメータを増やしても性能の改善は見られませんでした。
一方で、Chain of Thought(CoT)を使用する場合、モデルのサイズを大きくなるにつれて、標準的なプロンプトの性能を大幅に上回る向上が見られました。
また、GSM8Kデータセットにおいて、PaLMは540Bのパラメータを利用したときに、顕著な性能を示しました。
下表に示すように、Chain of Thought(CoT)と540BパラメータのPaLMモデルを組み合わせることで、 175Bを大規模な訓練セットでファインチューニングわれたGPT-3で達成された55%を上回る、58%という最高水準の性能を達成しました。
このように、思考連鎖プロンプトが様々な推論タスクの性能を向上させること、そして思考連鎖は、モデル規模が一定数以上に大きくなったときに現れる創発的特性であること、つまり、思考連鎖プロンプトの利点は十分な数のモデルパラメータ(100B程度)を持つ場合にのみ現れることがわかりました。
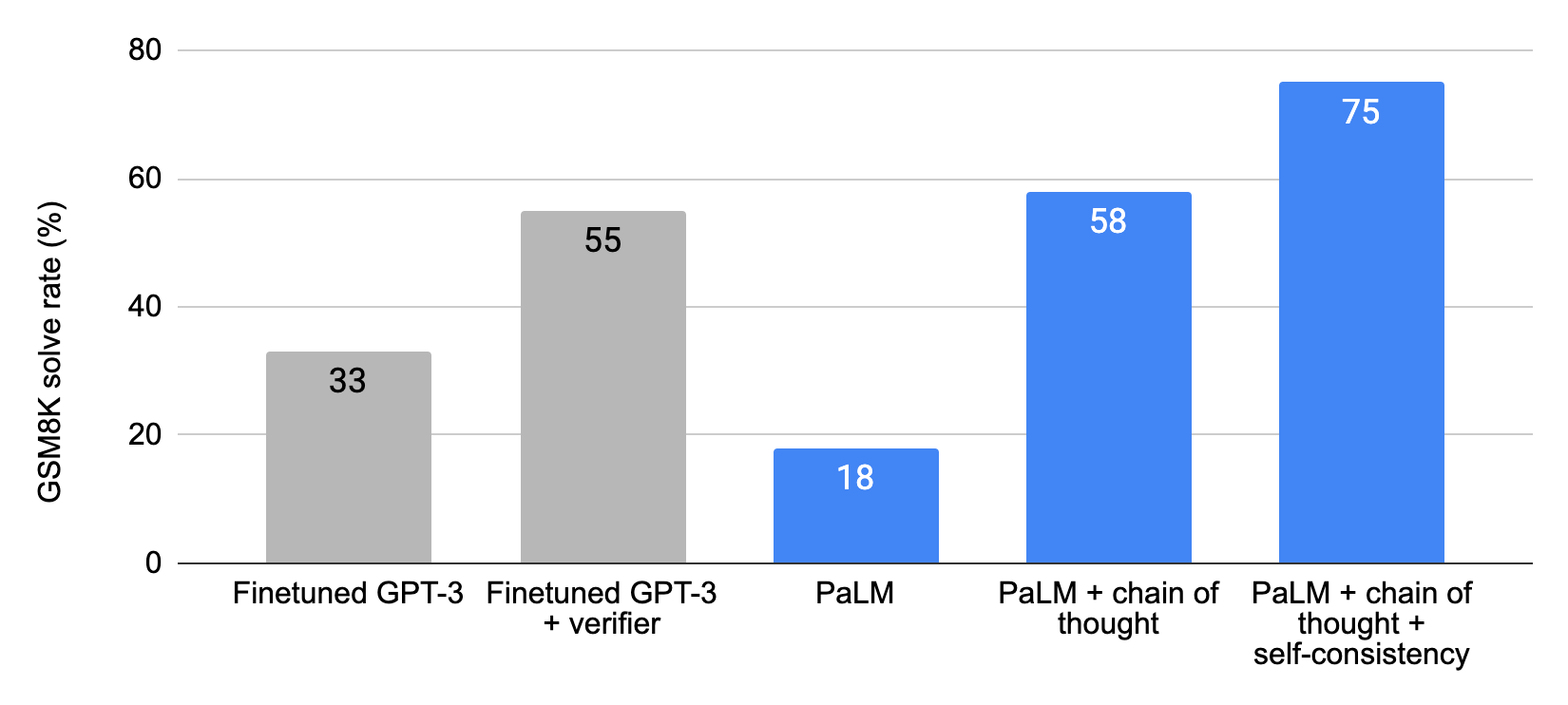
さらに、self-consistency という手法により、生成された推論プロセスの広範な集合の多数決を取ることで、Chain of Thought(CoT)の性能をさらに改善できることが示され、GSM8Kにおいて74%の精度が得られました。
常識推論
Chain of Thought(CoT)プロンプトの言語ベースの性質が、一般的な背景知識を前提とした常識推論にも適用できるのかどうかを検討しました。
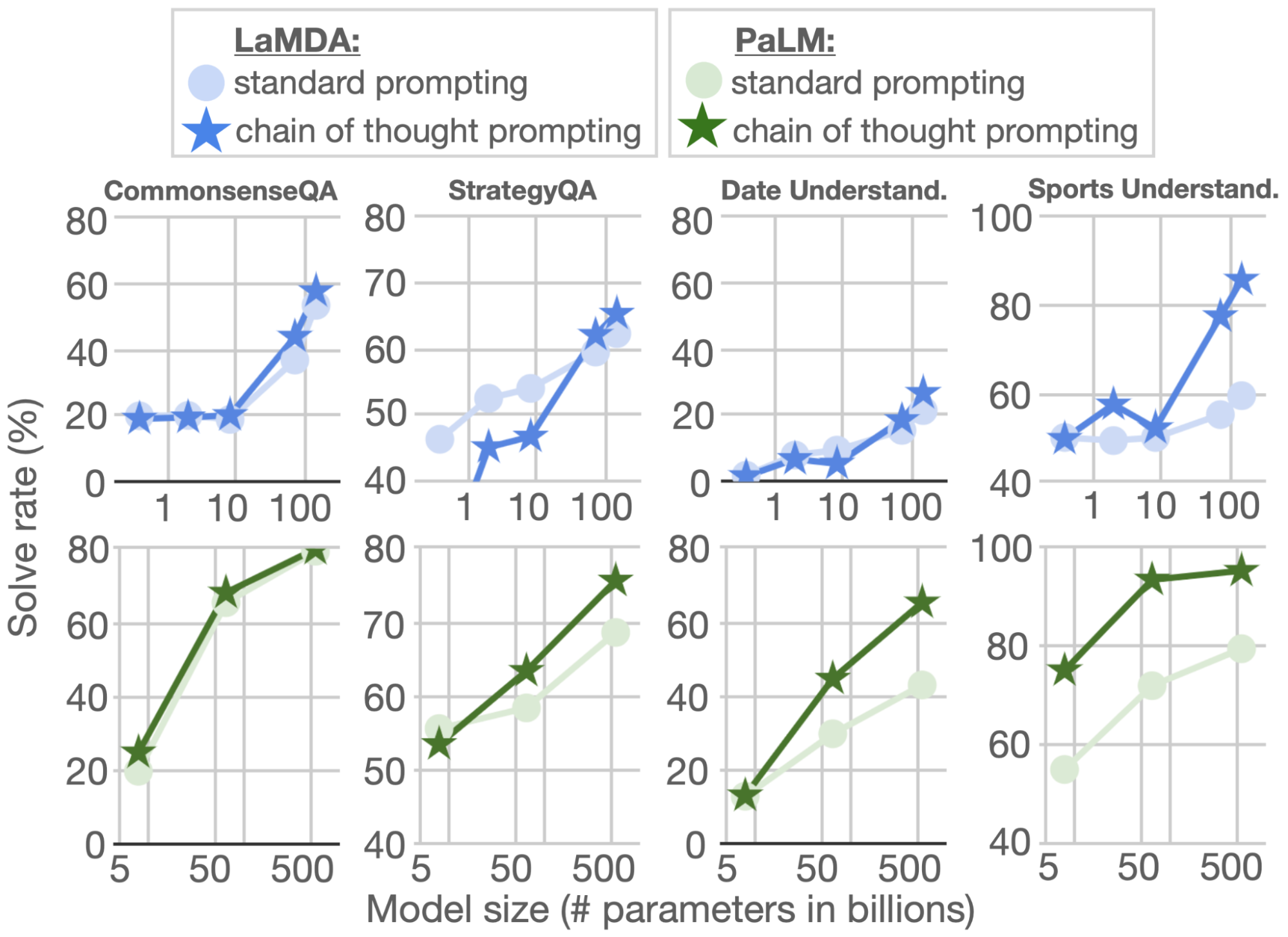
これらの評価には、CommonsenseQAおよびStrategyQAというベンチマークと、BIG-Bench collaborationにおける2つの領域固有のタスクである日付理解(date understanding)とスポーツ理解(sports understanding)を使用します。以下に例題を示す。

CommonsenseQA、StrategyQA、日付理解については、モデル規模が大きくなるにつれて性能が向上し、Chain of Thought(CoT)を採用することで、さらに向上が見られました。Chain of Thought(CoT)は、スポーツ理解において最大の改善をもたらし、PaLM 540Bの連鎖的思考能力は、標準的な方法を上回りました(95%対84%)。
結論
Chain of Thought(CoT)は、言語モデルが様々な推論タスクを実行する能力を向上させることができる、シンプルで広く適用可能な手法です。
算術推論と常識推論の実験を通して、連鎖的思考を促し、モデル規模が一定以上に大きくなると性能が急激に向上するという創発的特性であることがわかりました。
今後は、言語モデルが実行可能な推論タスクの範囲を広げることで、さらなる研究が促されることが期待されています。

コメント