ReActは、言語モデルが様々な言語推論や意思決定タスクを解決できるように、推論と行動を交互に実施する手法です。
背景
Chain-of-Thought(CoT)という手法は、独自の内部表現を使用するだけで、外部の情報を利用しないため、外部情報を元にして推論を行ったり、知識を更新したりする能力が制限されています。
このため、推論過程においてハルシネーションやエラーの伝播といった問題が生じる可能性があります。
ReActとは
ReActは、言語モデルを利用して、「行動」と「推論」を交互に実行します。
「行動(Actions)」によって外部環境(下の図の “Env”)からのフィードバック(Observations)が得られます。
一方で、「推論(Reasoning Traces)」はそのときの状況を判断して、将来によりよい「推論(Reasoning Traces)」と「行動(Actions)」を行えるように、モデルの内部状態に影響を与えます。
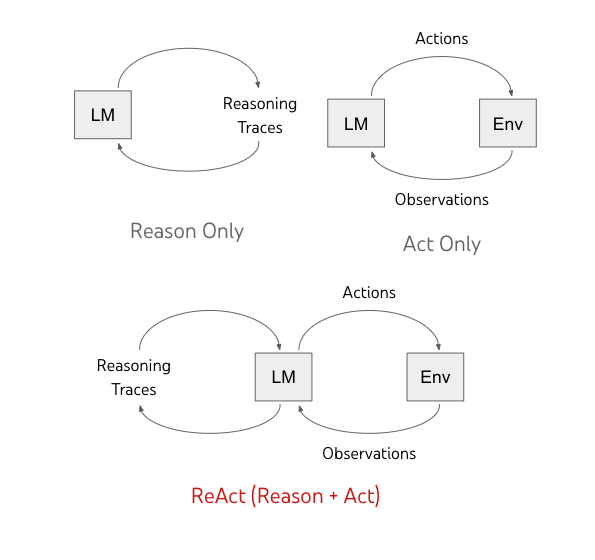
このように、推論と行動の相乗効果により、言語モデルは、行動のための計画を作成、推論を実行(reason to act)すると同時に、外部環境(Wikipediaなど)と相互作用し、推論に追加情報を取り込む(act to reason)ことを行なっています。
実験
以下のモデルを利用して、ReActを実行しました。
利用するモデル
- モデル
- PaLM-540B(ファイチューンを行っていない)
- ファイチューンを行ったモデル
- PaLM540Bモデルを使ってReActの軌跡(推論、行動)を生成し、うまくいった事例における軌跡を使ってより小さな言語モデル(PaLM-8/62B)をファインチューニングを行います。
結果
質問応答(HotPotQA)、事実検証(Fever)、テキストベースのゲーム(WebShop)、ウェブページナビゲーション(Wikipedia API)の4つのベンチマークにおいて、ReActの実証評価は、以下の通りです。
質問応答(HotPotQA)について、(a)Standard(ReasonもActも適用しない。), (b) Reason only, (c) Act only, (d)ReActをそれぞれ適用した結果を以下に示します。(d)ReActのみが正しい答えを導き出すことができました。

HotPotQAとFeverでは、モデルが対話できるWikipediaにアクセスすることで、ReActはReason-only(CoT)という手法と同等の性能を達成しつつ、行動生成モデル(Act-only)を上回りました。
最も良い結果を得た手法は、ReActとCoTの組み合わせた手法でした。
すべての手法は、ドメイン固有の最先端アプローチ(Supervised SoTA)からはまだ大きく離れているため、ReActの潜在的な可能性を引き出すには、より多くの人間が書いたデータでファインチューニングするのが良い方法かもしれません。

ALFWorldとWebShopにおいて、ReActは、既存の手法と比較して、それぞれ34%と10%の成功率が改善しました。

ファインチューニングを行わないとき、ReActは4つの方法(Standard, CoT, Act, ReAct)の中で最も性能が悪くなりました。
しかし、3,000例でファインチューニングすると、ReActは4つの手法の中でもっともよい結果を残しました。またPaLM-8Bにおいて、ファインチューニングされたReActは、PaLM-62Bを用いたすべての手法を上回り、PaLM-62BでファインチューニングされたReActは540Bのすべての手法を上回りました。ReActは知識推論のより一般化可能なスキルであるウィキペディアから情報にアクセスする行動をモデルに教えるからです。
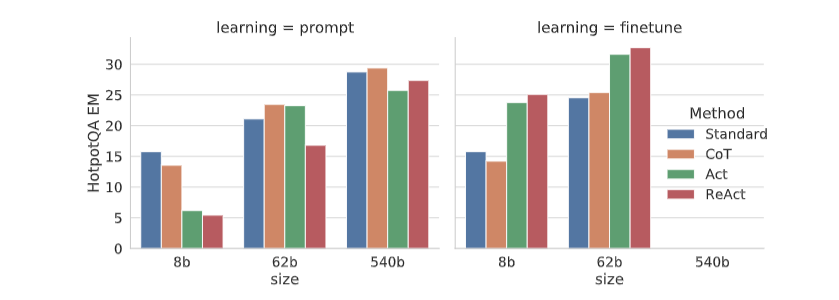
対照的に、StandardやCoTにおけるファインチューニングは、PaLM8/62Bの両方において性能が悪化しました。間違った知識を記憶するようモデルに教えていることがあるからです。
結論
ReActは、言語モデル内で思考、行動、環境からのフィードバックをモデル化することの実現可能性を示して、環境との相互作用を必要とするタスクを解決できる汎用性の高い手法です。
これからの課題として、大規模なマルチタスク訓練や、ReActと同様に強力な報酬モデルとの融合などのアプローチを通じて、より広範な具現化タスクに取り組むために言語モデルを活用すると、論文では述べられています。
大規模言語モデル、ChatGPTに関するご相談は株式会社リブレストに
株式会社リブレストでは、大規模言語モデル、ChatGPTに関するご相談を受け付けています。

コメント